
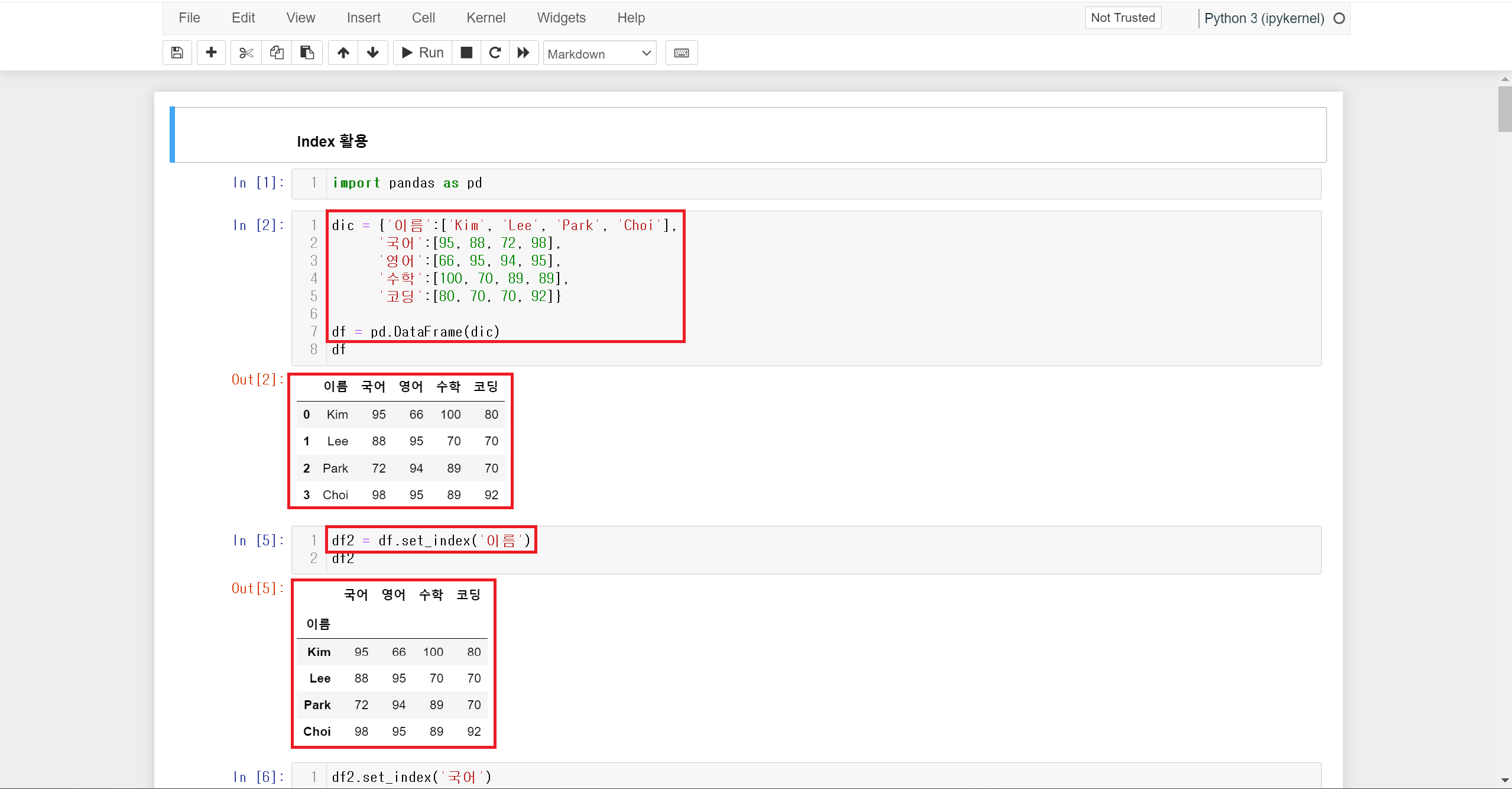
먼저 DataFrame을 하나 생성해 줍니다. DataFrame을 생성할 때 인덱스를 따로 지정해주지 않으면 default로 정수형으로 0번부터 지정됩니다. 인덱스의 원래 용도는 row 구별을 위한 것이라 인덱스는 유일성이 존재해야 합니다.
만약 이미 생성된 DataFrame의 인덱스를 변경하기 위해서는 set_index() 메서드를 활용하면 됩니다.
DataFrame 이름.set_index('column 이름') 형식으로 작성하면 지정한 column의 값을 인덱스로 바꿔줍니다.
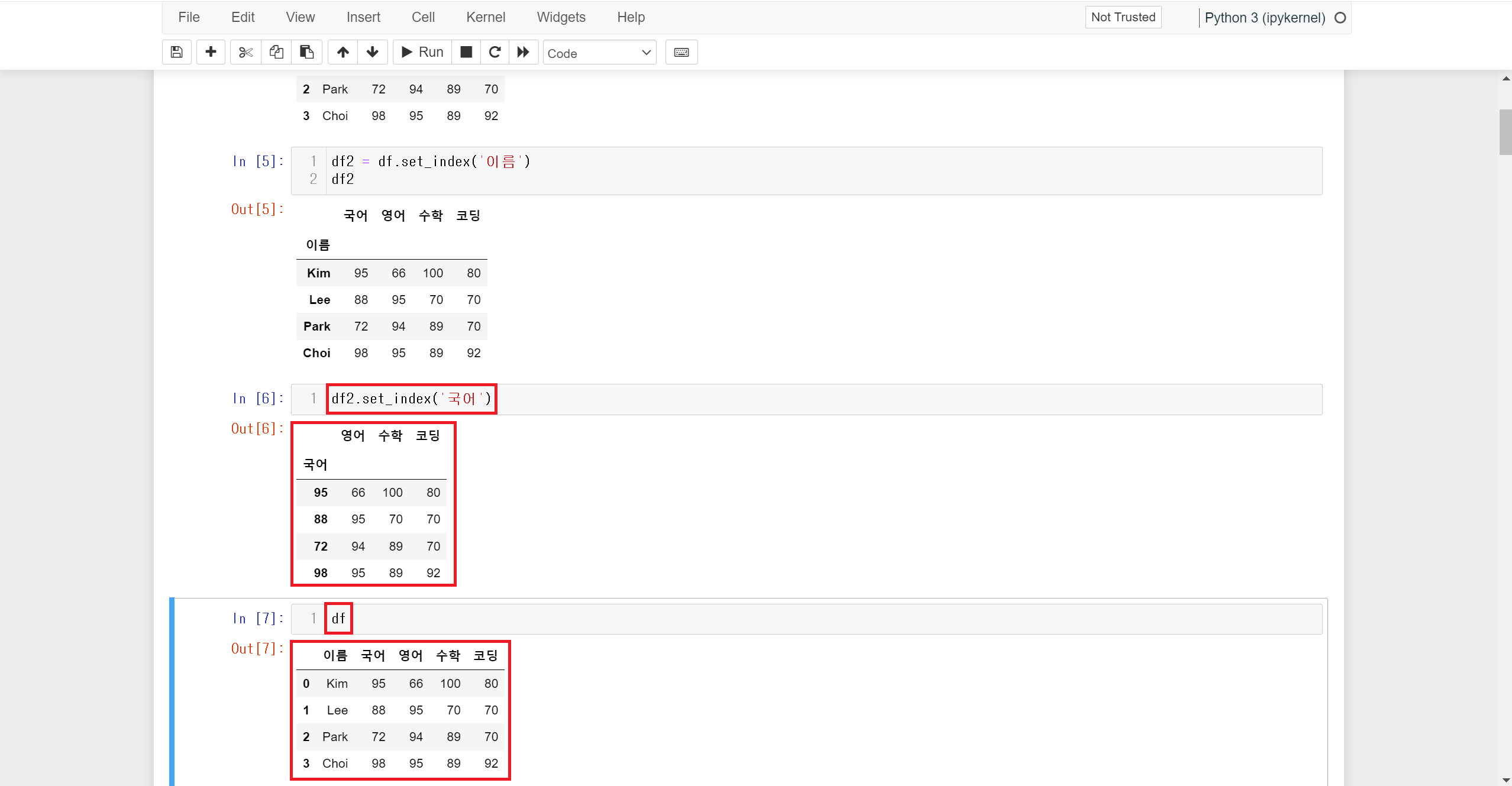
만약 set_index() 메서드를 적용한 상태에서 한 번 더 다른 column 이름으로 set_index() 메서드를 사용하면 이전 인덱스가 사라지게 되므로 사용하실 때 주의하시길 바랍니다.
set_index() 메서드로 column을 인덱스로 바꿔도 실제로는 적용되지 않는 것을 볼 수 있습니다.
set_index() 메서드도 마찬가지로 inplace 옵션을 True로 변경해 줘야 실제도 적용됩니다.
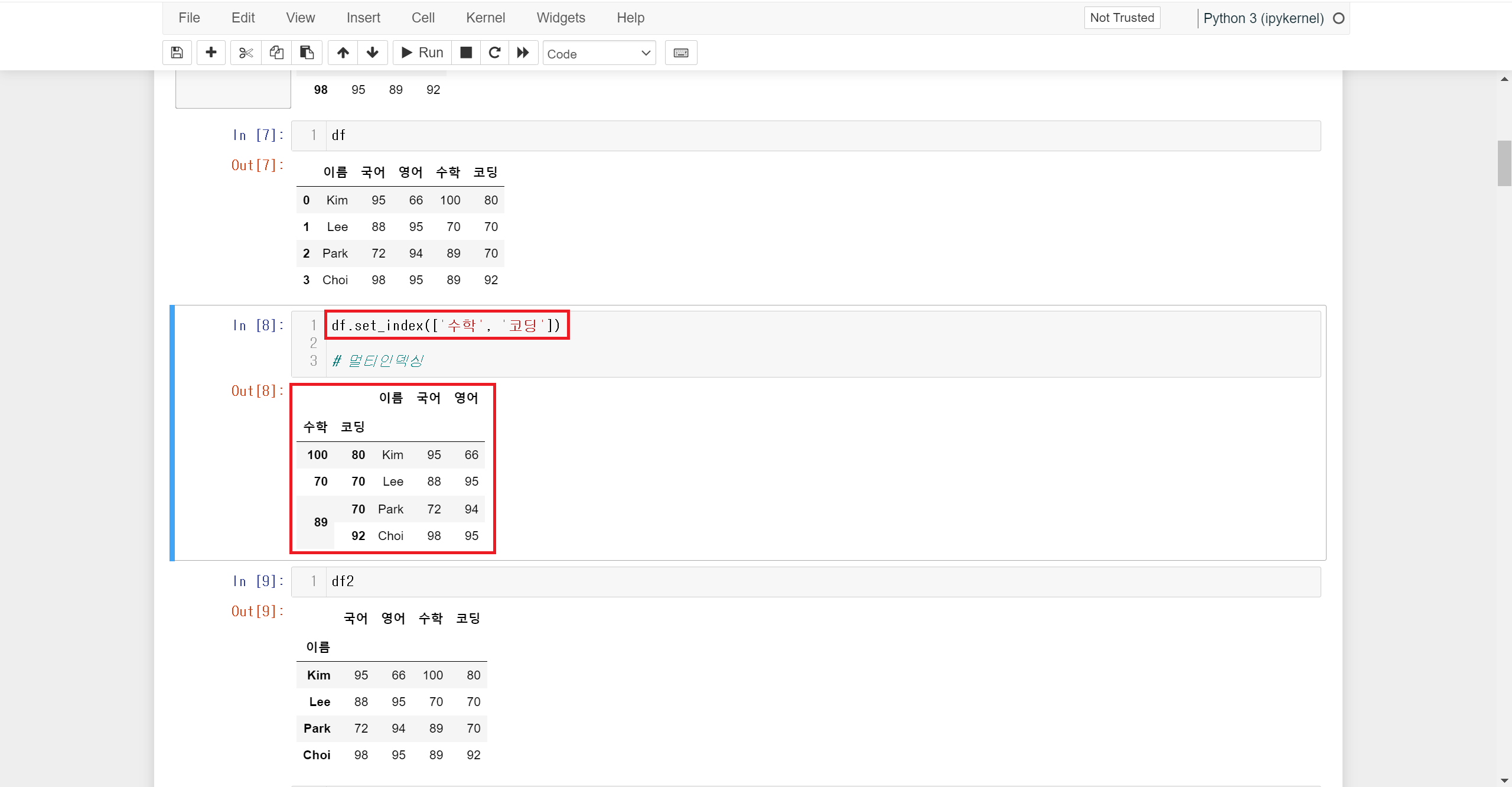
만약 인덱스를 여러 개 사용하여 row를 구분할 수도 있습니다. 이를 멀티 인덱싱이라고 합니다.
set_index() 메서드를 사용할 때 여러 column 이름을 묶어서 지정해 주면 지정된 column 내용이 모두 인덱스로 활용되어 row를 구분해 줍니다.

만약 변경한 인덱스를 정수형으로 변경하려면 reset_index() 메서드를 사용하면 됩니다.
DataFrame 이름.reset_indes() 형식으로 작성하면 해당 DataFrame의 인덱스가 원래의 정수형으로 변경되고 기존의 인덱스는 column으로 이동하게 됩니다.
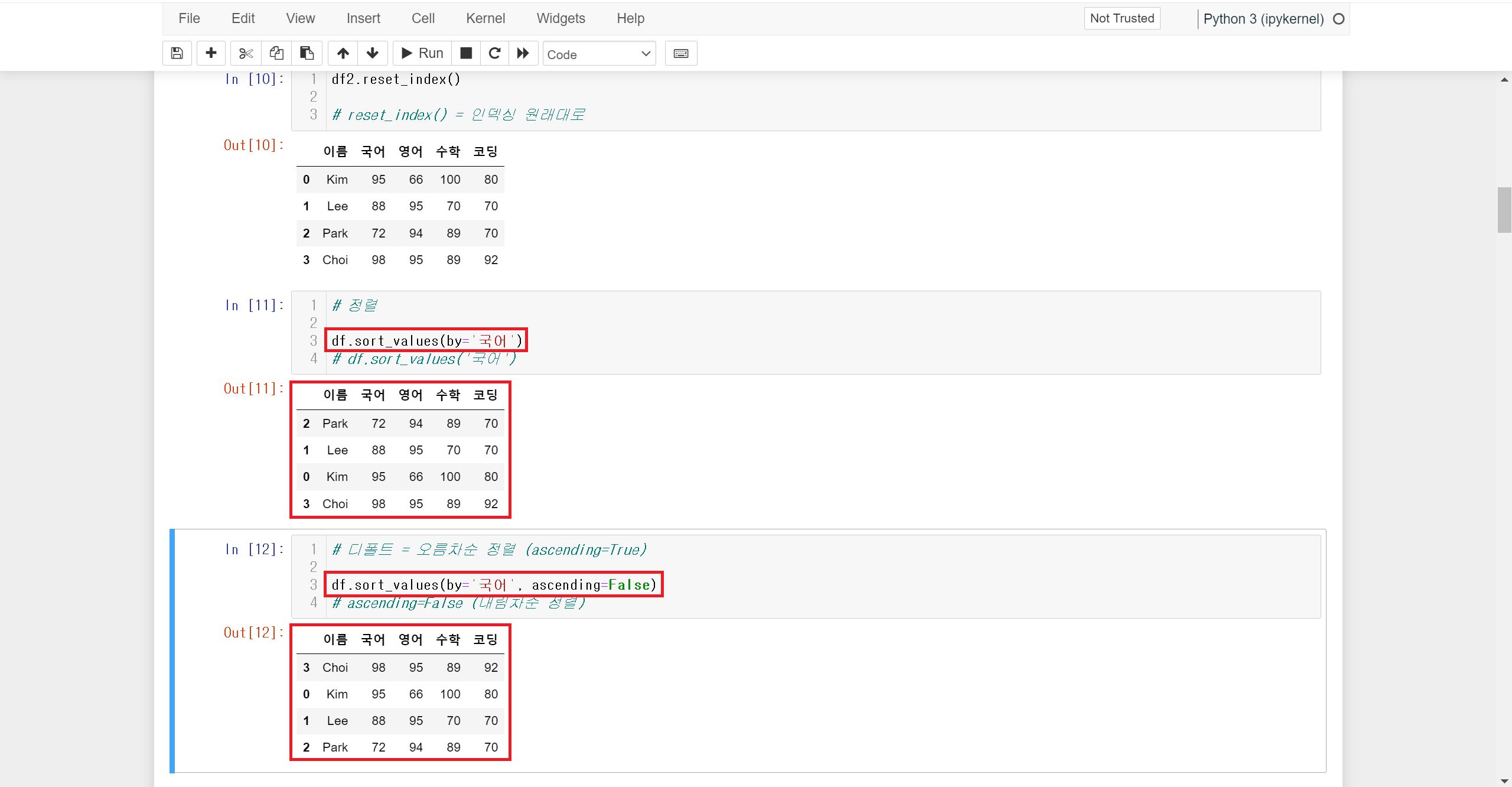
DataFrame을 정렬할 수도 있습니다. 정렬은 다방면을 많이 활용됩니다.
DataFrame을 정렬할 때는 sort_values() 메서드를 활용하면 됩니다.
DataFrame 이름.sort_values(by = 'column 이름') 형식으로 작성하면 해당 column의 값에 따라 오름차순으로 정렬됩니다. 만약 내림차순으로 정렬하기 위해선 default 값이 True로 설정되어 있는 ascending 옵션을 False로 변경해 주면 됩니다.
'Data Science > Data Analysis' 카테고리의 다른 글
| [파이썬으로 하는 데이터 분석] 13. 파일 다루기 - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.12.02 |
|---|---|
| [파이썬으로 하는 데이터 분석] 12. 산술연산 - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.11.26 |
| [파이썬으로 하는 데이터 분석] 11. Function Mapping & 그룹화 - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.11.04 |
| [파이썬으로 하는 데이터 분석] 10. Aggregation - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.10.15 |
| [파이썬으로 하는 데이터 분석] 8. 추가 & 변경 - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.10.08 |
| [파이썬으로 하는 데이터 분석] 7. 선택 - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.10.07 |
| [파이썬으로 하는 데이터 분석] 6. Pandas 자료구조 - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.09.24 |
| [파이썬으로 하는 데이터 분석] 5. Matplotlib - 우당탕탕 개발자 되기 프로젝트 (0) | 2023.09.23 |



